트랜스포머 이해하기: 단계별 수학 예제 — 1부
본 내용은 gopenai.com의 Fareed Khan 블로그에서 가져온 내용으로 일부 추가와 번역한 내용으로 많은 도움이 되기 바랍니다
트랜스포머 아키텍처가 무섭게 보일 수 있다는 것을 이해하며 YouTube나 블로그에서 다양한 설명을 접했을 수 있습니다. 그러나 내 블로그에서는 포괄적 인 수치 예제를 제공하여 이를 명확히 하기 위해 노력할 것입니다. 이를 통해 트랜스포머 아키텍처에 대한 이해를 단순화할 수 있기를 바랍니다.
내 자신의 개념을 명확히 하는 데 도움이 되는 명확한 설명을 제공한 HeduAI에 감사드립니다!
시작하자!
입력 및 위치 인코딩
입력을 결정하고 이에 대한 위치 인코딩을 계산하는 초기 부분을 해결해 보겠습니다.

1단계(데이터 정의)
초기 단계는 데이터 세트(말뭉치)를 정의하는 것입니다.

데이터 세트에는 왕좌의 게임 TV 쇼에서 가져온 3개의 문장(대화)이 있습니다. 이 데이터 세트는 작아 보일 수 있지만 그 크기는 실제로 다가오는 수학 방정식을 사용하여 결과를 찾는 데 도움이 됩니다.
2단계(어휘 크기 찾기)
어휘 크기를 결정하려면 데이터 세트에서 고유한 단어의 총 수를 식별해야 합니다. 이는 인코딩(즉, 데이터를 숫자로 변환)에 매우 중요합니다.

여기서 N은 모든 단어의 목록이고 각 단어는 단일 토큰입니다. 데이터 세트를 토큰 목록으로 나눕니다(예: N 찾기).

N으로 표시된 토큰 목록을 얻은 후 공식을 적용하여 어휘 크기를 계산할 수 있습니다.

set 연산을 사용하면 중복을 제거하는 데 도움이 되며 고유한 단어를 계산하여 어휘 크기를 결정할 수 있습니다. 따라서 주어진 목록에 23개의 고유한 단어가 있으므로 어휘 크기는 23입니다.
3단계(인코딩 및 포함)
우리는 데이터 세트의 각 고유 단어에 정수를 할당합니다.

전체 데이터 세트를 인코딩한 후 입력을 선택할 차례입니다. 말뭉치에서 다음과 같은 문장을 선택합니다.
"왕좌의 게임을 할 때"
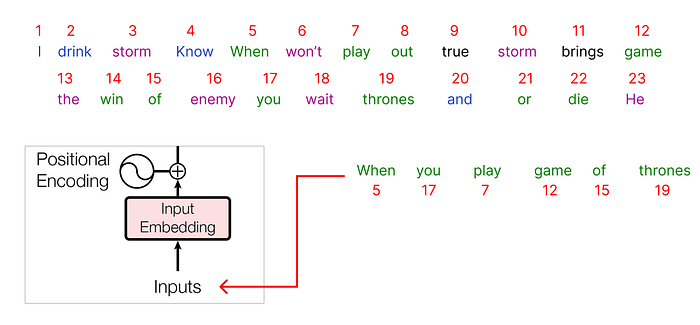
입력으로 전달된 각 단어는 인코딩된 정수로 표시되며 각 해당 정수 값에는 연결된 임베딩이 첨부됩니다.
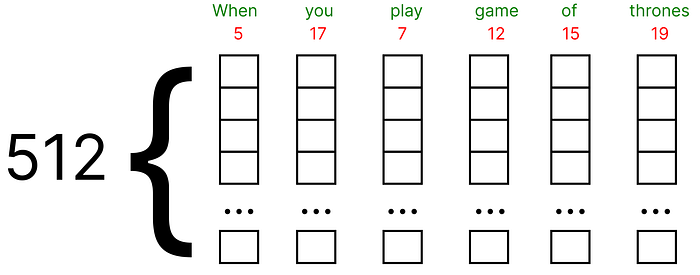
- 이러한 임베딩은 Google Word2vec (단어의 벡터 표현)을 사용하여 찾을 수 있습니다. 수치 예제에서 (0과 1) 사이의 임의의 값으로 채워진 각 단어에 대해 벡터를 포함한다고 가정합니다.
- 또한, 원래 논문은 임베딩 벡터의 512 차원을 사용하며, 우리는 매우 작은 차원, 즉 수치 예의 경우 5를 고려할 것입니다.
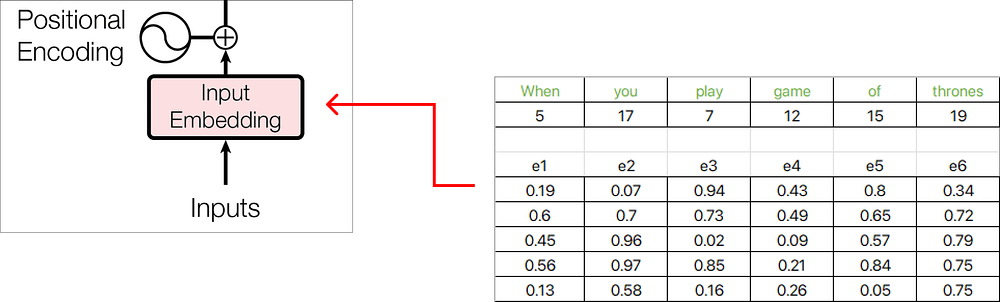
이제 각 단어 임베딩은 차원 5의 임베딩 벡터로 표현되며, 값은 Excel 함수 RAND()를 사용하여 난수로 채워집니다.
4단계(위치 임베딩)
첫 번째 단어, 즉 "When"을 고려하고 이에 대한 위치 임베딩 벡터를 계산해 보겠습니다.
위치 임베딩에는 두 가지 공식이 있습니다.
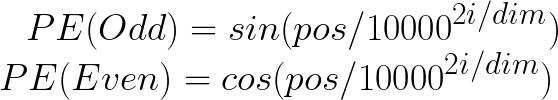
첫 번째 단어인 "When"의 POS 값은 시퀀스의 시작 인덱스에 해당하므로 5이 됩니다. 또한 i의 값이 짝수인지 홀수인지에 따라 PE 값을 계산하는 데 사용할 공식이 결정됩니다. 차원 값은 임베딩 벡터의 차원을 나타내며, 이 경우 <>입니다.

위치 임베딩 계산을 계속하면서 다음 단어 "you"에 pos 값 1을 할당하고 시퀀스의 각 후속 단어에 대해 pos 값을 계속 증가시킵니다.
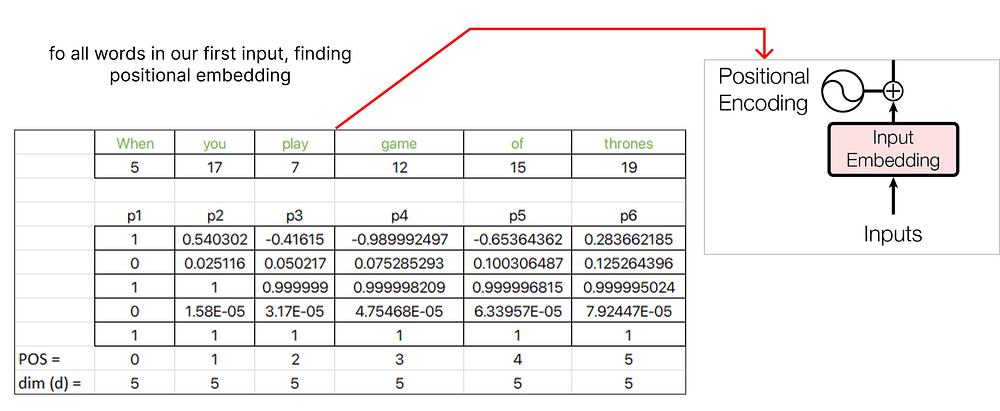
위치 임베딩을 찾은 후 원래 단어 임베딩과 연결할 수 있습니다.
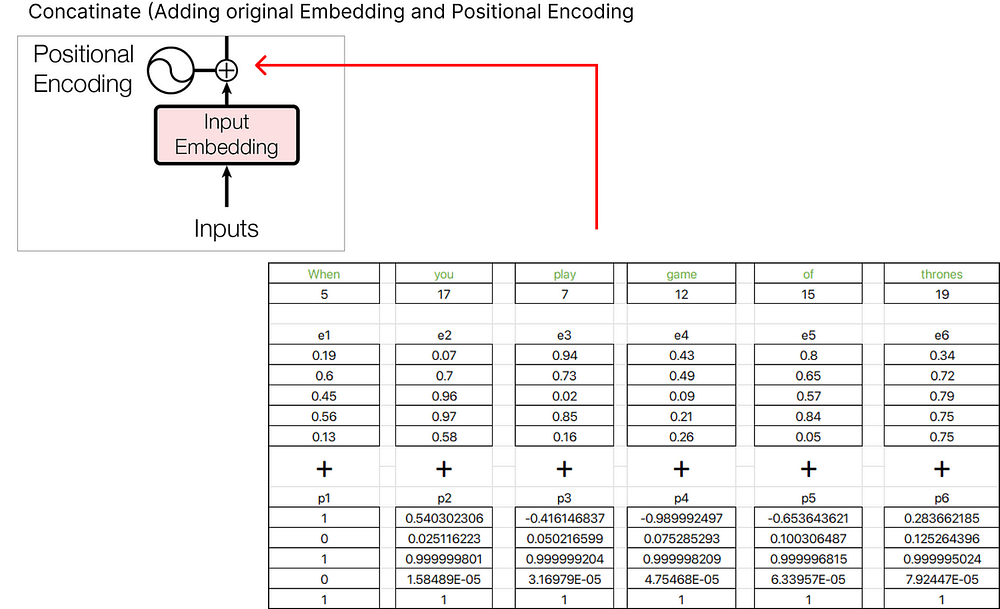
The resultant vector we obtain is the sum of e1+p1, e2+p2, e3+p3, and so on.
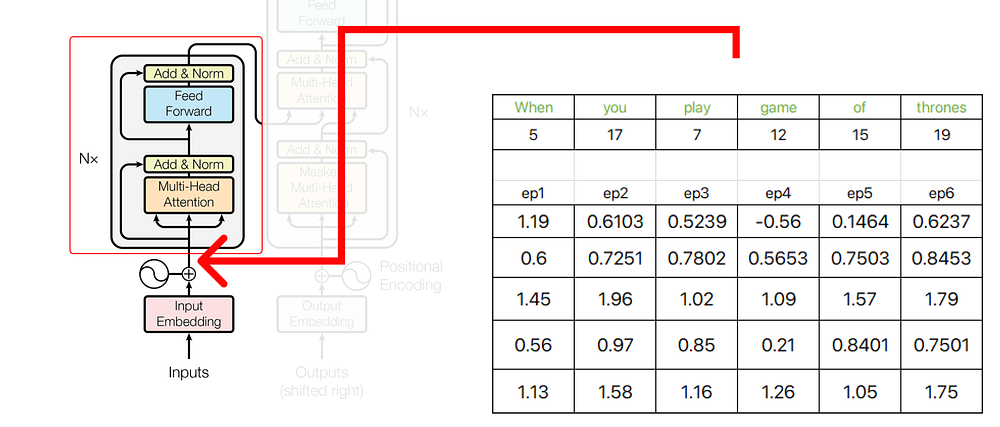
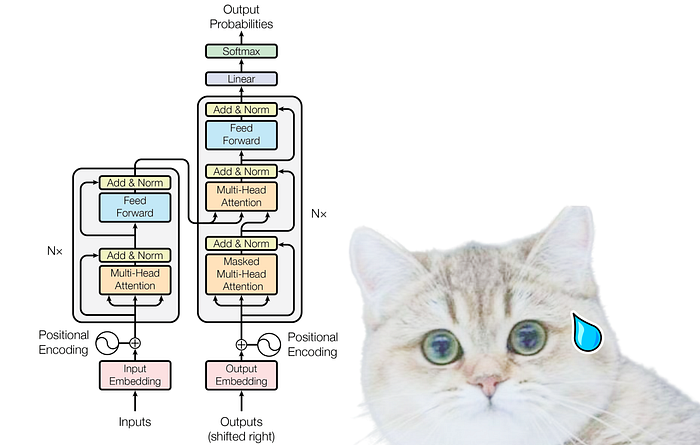
트랜스포머 아키텍처의 초기 부분의 출력은 인코더에 대한 입력 역할을 합니다.
인코더
인코더에서는 쿼리, 키 및 값의 행렬과 관련된 복잡한 작업을 수행합니다. 이러한 작업은 입력 데이터를 변환하고 의미 있는 표현을 추출하는 데 중요합니다.
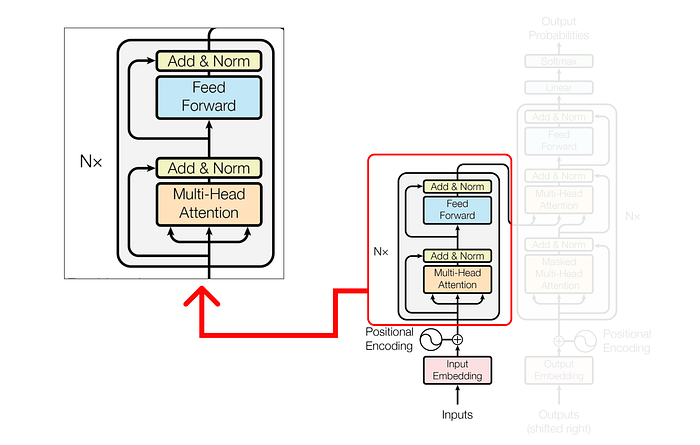
다중 헤드 주의 메커니즘 내부에서 단일 주의 계층은 몇 가지 주요 구성 요소로 구성됩니다. 이러한 구성 요소는 다음과 같습니다.

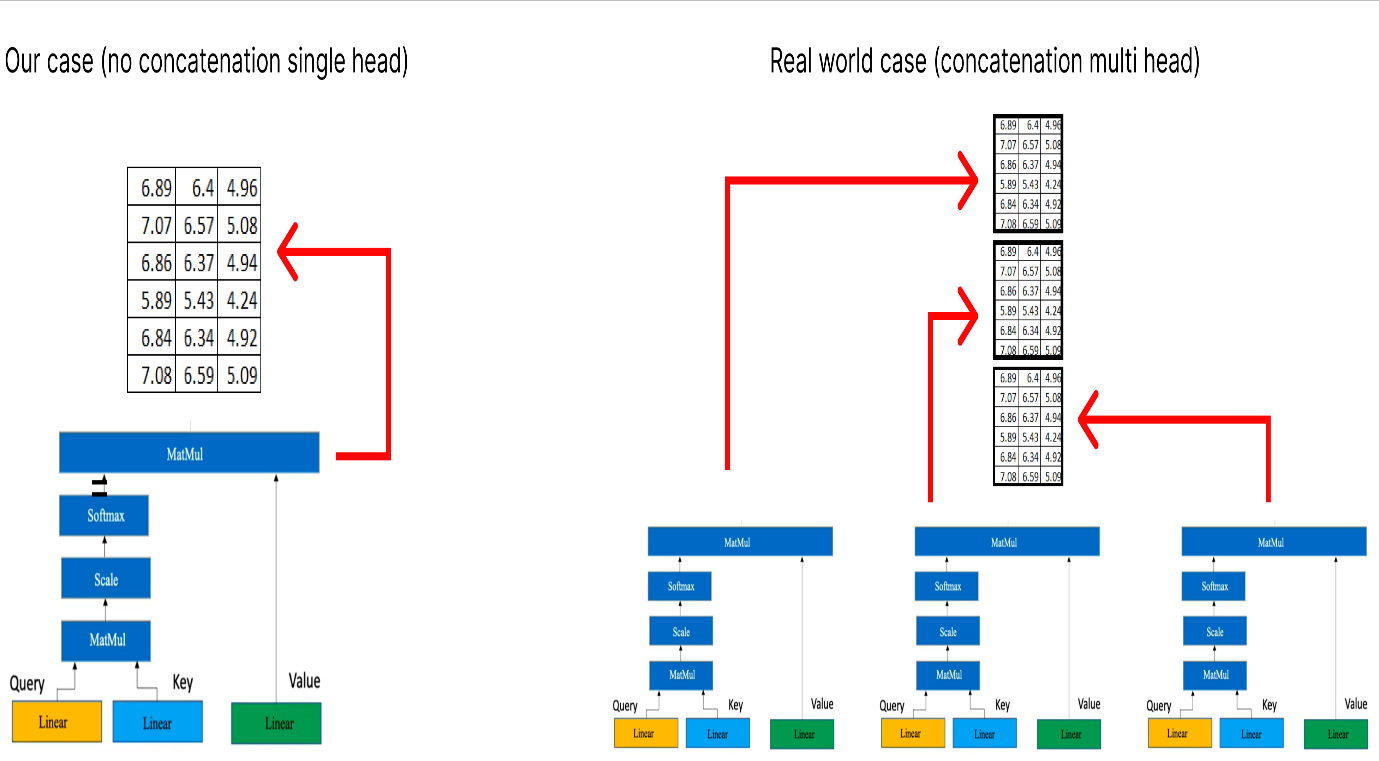
노란색 상자는 단일 주의 메커니즘을 나타냅니다. 여러 개의 헤드에 주의를 기울이는 것은 여러 개의 노란색 상자가 있다는 것입니다. 이 수치 예제의 목적을 위해 위의 다이어그램에 표시된 대로 하나(즉, 단일 머리 주의)만 고려합니다.
1단계(단일 수두 주의 수행)
주의 계층에는 세 가지 입력이 있습니다.
- 쿼리
- 열쇠
- 값
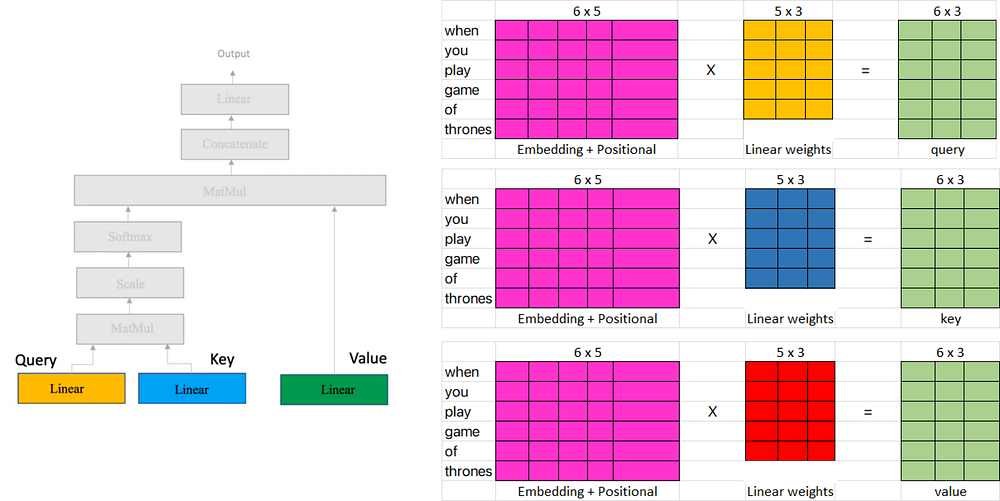
위에 제공된 다이어그램에서 세 개의 입력 행렬(분홍색 행렬)은 단어 포함 행렬에 위치 임베딩을 추가하는 이전 단계에서 얻은 전치 출력을 나타냅니다.
반면에 선형 가중치 행렬(노란색, 파란색 및 빨간색)은 주의 메커니즘에 사용되는 가중치를 나타냅니다. 이러한 행렬은 열에 대해 임의의 수의 차원을 가질 수 있지만 행 수는 곱셈을 위한 입력 행렬의 열 수와 같아야 합니다.
우리의 경우 선형 행렬(노란색, 파란색 및 빨간색)에 임의의 가중치가 포함되어 있다고 가정합니다. 이러한 가중치는 일반적으로 무작위로 초기화된 다음 역전파 및 경사하강과 같은 기술을 통해 학습 프로세스 중에 조정됩니다.
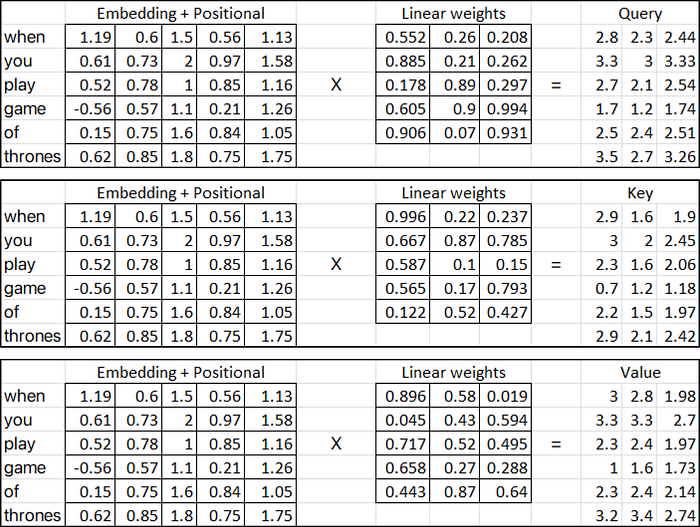
이제 (쿼리, 키 및 값 메트릭)을 계산해 보겠습니다.
주의 메커니즘에 쿼리, 키 및 값 행렬이 있으면 추가 행렬 곱셈을 진행합니다.

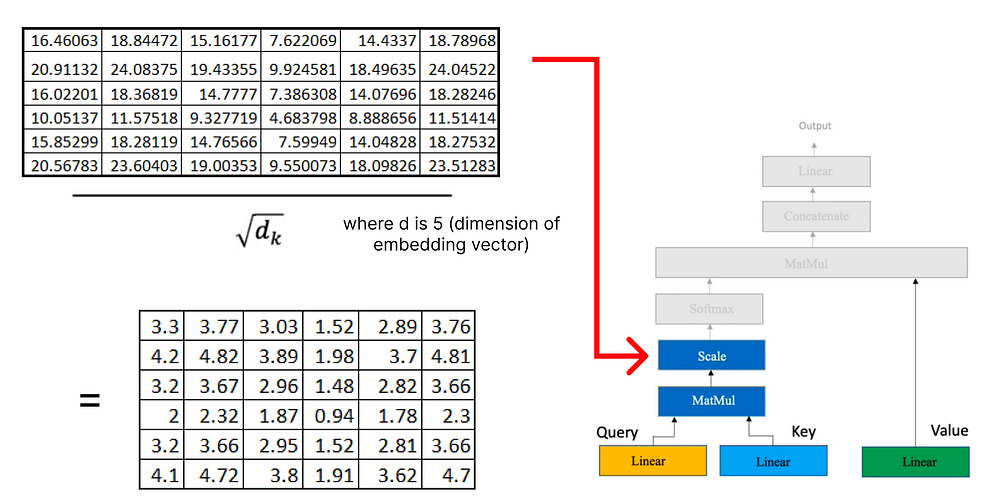

이제 결과 행렬에 이전에 계산한 값 행렬을 곱합니다.
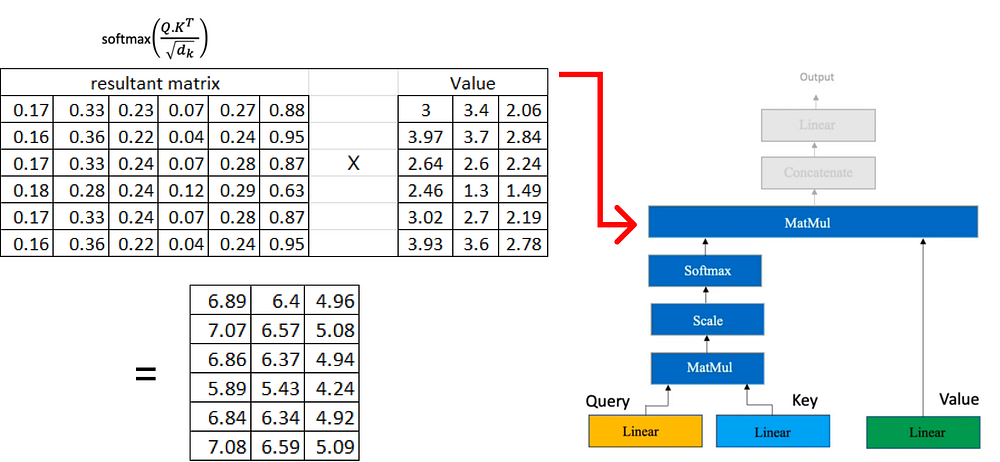
각각 차원 행렬(6x3)을 생성하는 여러 머리 주의가 있는 경우 다음 단계는 이러한 행렬을 함께 연결하는 것입니다.
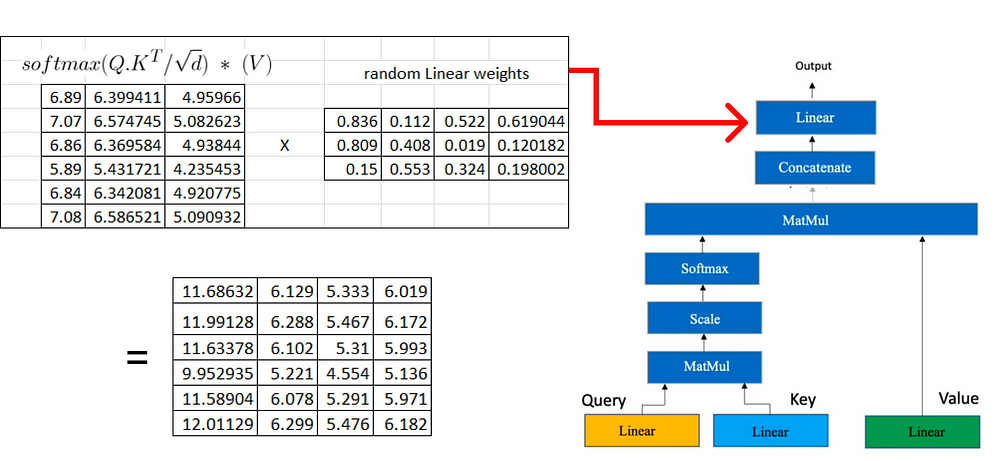
다음 단계에서는 쿼리, 키 및 값 행렬을 가져오는 데 사용되는 프로세스와 유사한 선형 변환을 다시 한 번 수행합니다. 이 선형 변환은 다중 헤드 어텐션으로부터 얻어진 연접 행렬에 적용된다.
블로그가 이미 길어지고 있으므로 다음 부분에서는 인코더 아키텍처와 관련된 단계에 대해 논의하는 데 초점을 맞출 것입니다.
PART2를 기대하며, gopenai.com의 Fareed Khan님께 감사드립니다.
