
1. Loading Library and Data
1-1. Load Library
- LlamaIndex: (이전의 GPT Index)는 비공개 또는 도메인별 데이터를 수집, 구성 및 액세스하기 위한 LLM 애플리케이션용 데이터 프레임워크입니다.
- 왜 LlamaIndex인가?
- 핵심적으로 LLM은 사람과 추론된 데이터 사이에 자연어 인터페이스를 제공합니다.
- 광범위하게 사용 가능한 모델은 Wikipedia 및 메일링 목록에서 교과서 및 소스 코드에 이르기까지 공개적으로 사용 가능한 방대한 양의 데이터에 대해 사전 교육을 받습니다.
- LLM 위에 구축된 애플리케이션은 개인 또는 도메인별 데이터로 이러한 모델을 보강해야 하는 경우가 많습니다. 안타깝게도 해당 데이터는 격리된 애플리케이션과 데이터 저장소에 분산될 수 있습니다. API 뒤에 있거나 SQL 데이터베이스에 있거나 PDF 및 슬라이드 데크에 갇혀 있습니다.
- 설치는:
- pip install llama-index
- Text를 위한 Data는 ChatGPT에서 약간의 질문에 대한 답을 별도의 Text 파일로 저장합니다
- 아래코드에서는 .//llmData로 정했습니다
- Openai의 API Key를 사용합니다.
- Openai에서 받을 수 있으며, 방법은 internet에서 찾아보세요
1-2. Load data
- Text를 위한 Data는 ChatGPT에서 약간의 질문에 대한 답을 별도의 Text 파일로 저장합니다
- 아래코드에서는 .//llmData로 정했습니다

1-3. GPTVectorStoreIndex
- llama_index 모듈에서 GPTVectorStoreIndex 클래스를 불러옵니다.
- GPTVectorStoreIndex는 GPT를 기반으로 문서를 벡터로 변환하고, 이를 인덱싱하는 클래스입니다.
- 다음으로 from_documents 메소드를 사용하여 documents_txt라는 텍스트 문서를 사용해 인덱스를 생성합니다.
- 이 메소드는 문서들을 읽어서 각 문서를 벡터로 변환하고, 이 벡터들을 저장하여 나중에 빠른 검색이 가능하게 합니다.
- 마지막으로, as_query_engine 메소드를 사용하여 인덱스를 쿼리 가능한 형태로 변환합니다.
- 이렇게 하면 특정 쿼리에 대한 문서 검색을 수행할 수 있게 됩니다.
- 이 쿼리는 보통 사용자의 질문이나 검색 키워드가 됩니다.
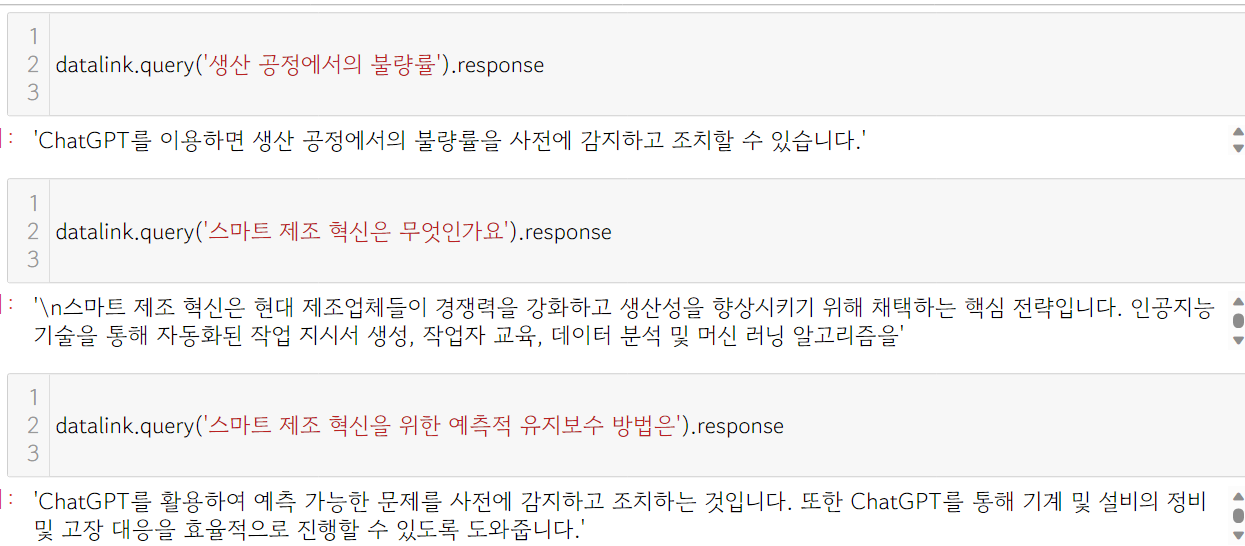
- GPT를 이용하여 문서 검색 시스템을 구축하는 예로 사용자의 질문이나 키워드에 가장 잘 맞는 문서(Data)를 찾아주는 역할을 합니다.

2. Prompt and Response
PS) Llama2를 사용한 사례는 조만 간에 올릴 예정입니다(아주 쉬워요~)

0개의 댓글
로그인
로그인 이후 댓글 쓰기가 가능합니다.